Case study: Archiving an old multi-site WordPress instance
 Nils Norman Haukås
Nils Norman HaukåsWith this post I want to share a recent adventure I had with archiving an old WordPress site. I time traveled with Docker, I did regex surgery on a database dump and bestowed admin access on myself by editing a functions.php file. Wowzer!
I have previously written about how I helped archive sites for the research organisation NORCE (here’s that story).
Time passed and NORCE approached us again for help to archive more sites. These sites were scheduled to be phased out and deleted. This new work consisted of archiving one static site and ten WP inside one multisite WP instance.
An old WP instance.

One might rightly ponder, why was it important to archive these sites? NORCE is a very large institution, a fusion of previous institutions with a lot of people, a lot of research activity and a lot of history. Therefore it’s less work to fully archive these sites instead of making really, really sure that someone won’t need some deleted content sometime in the future.
Onboarding with Christmas looming #
Digital agencies tend to get very busy before Christmas because clients tend to want everything done before Christmas. And it’s no different at Netlife. It’s a good sign and challenging nonetheless.
Since we were so busy Netlife hired help from Umoe Consulting. We were lucky to get help from a Danish consultant named Allan.
We scheduled a brief onboarding meeting where the agenda was, “Nils explains everything about the archiving work to be done.”
Properly onboarding developers into projects is equally tricky and important. The better the project handover, the better new project members will be able to build upon the existing work and avoid going down previously explored dead-ends.
This time around I was helped a lot by my time invested into writing not only a proper readme file for the existing project work but even a blog post covering the underlying, broader thought work. Not only was there a description of the work already done but also why it was done that way.
What was scheduled to be a 30min action-packed onboarding meeting became a 15min briefing on the new work to be done where I introduced the work and the sources to read. And then Allan was off to a good start. Following that we kept in touch through chat.
Good documentation is gold.
Part one: Ready, set, let’s archive! #
Allan quickly finished archiving the first static site which was the first site of eleven. However, the remaining sites running on the multi-site WP proved difficult to archive in a number of unforeseen ways.
In this phase Allan worked very much on his own because I was busy with other projects. While Allan was clocking in the hours, I contributed chat-based help on troubleshooting issues and brainstorming ideas.
The ten WP sites were located as sub-urls on a main WP url, like so:
- wpms.example.org <– root site
- wpms.example.org/site1
- wpms.example.org/site2
Issues encountered when trying to archive these live sites:
-
The sites enforced https but did not provide an encrypted connection. This is an understandable issue since this site was old and unmaintained. Running the wget command line program to start web crawling and archiving these sites threw a lot of errors, which was then fixed with an ignore flag for SSL errors.
-
One of the WP sites had non-ascii letters like æ, ø and å in its urls which threw more errors in the
wgetcommand.- We considered using anyproxy to urlencode any links in the html before it was returned to wget to mask any non-ascii letters in links. Wget would just see plain links and follow them when traversing. Additionally we would have to also urldecode requests in the proxy to regain masked letters in urls before calling the live site. In the end, we didn’t have time to complete this approach.
-
The root site had only a “restricted access” notice and no links to the sub-sites. Usually, I would just start
wgetat the site’s main page and the program will automatically jump from link to link until it has all the content (also, termed crawling). With this closed-off frontpage Allan was forced to runwgetonce per sub-site. This ended up confusing wget’s “convert-links for offline” step, which resulted in links in the static archive that would send you to the live site instead of the archived pages. There’s no use having such links to the live site when it’s scheduled to be removed. Allan tried to fix this by running search-and-replace commands on the downloaded .html files but it wasn’t working quite well and we suspected that it wasn’t a robust fix. -
Also, we saw that the
wgetscript would traverse the sites either too fast or somehow access sub-urls which could trigger WP to block the ip for a while.
It was increasingly clear to us that archiving by traversing the live site was not the right approach.
Part two: Running the site locally with Docker #
We requested and received a full copy of the WordPress instance quite early on. However, because our initial attempts at running it locally proved hard and time-consuming we decided to first try and create a static archive from the live site.
The astute reader would now know that we failed at archiving the live site. It might look plain to see in hindsight, but at the time we thought that we made the most efficient bet by archiving the live site. We lost that bet and returned to resurrecting this old WP instance.
It was now mid-Christmas. Allan didn’t have any time left to spend on the project, but I had a couple of work days available to actually get my hands into this work, and see if I could finish it before Christmas.
I got to work by applying docker and docker-compose, which are my go-to tools when I need to run web services locally. Web services can be very particular about the server environment they need around them, like file paths, configuration variables, program versions and so on. Docker is good at appeasing fickle programs so they’ll run.
docker-compose.yml : This file describes two services that should start up together, specifically one for a database and one for the server.
version: "3"
services:
database-service:
image: mysql:5.7
volumes:
# Mount a local folder containing a copy of the
# .sql database.
- ./wp-db-dump:/docker-entrypoint-initdb.d:cached
environment:
# Setting a silly password because it won't be
# deployed anywhere.
- MYSQL_ROOT_PASSWORD=just-a-local-password
- MYSQL_DATABASE=wp_multisite
server:
# Build docker image based on adjacent Dockerfile.
build: ./
ports:
- "5000:80"
volumes:
- ./wp-dump/usr/share/wordpress:/var/www/html/:cached
Dockerfile, this file describes the server environment. As, you can see we’re mostly relying on the official image’s default behavior.
# extend the official php image.
FROM php:7.3-apache
# Activate .htaccess module(s) that WordPress needs.
RUN a2enmod rewrite
With these two files in place I ran docker-compose up in the terminal and used my web browser to navigate to localhost:5000.
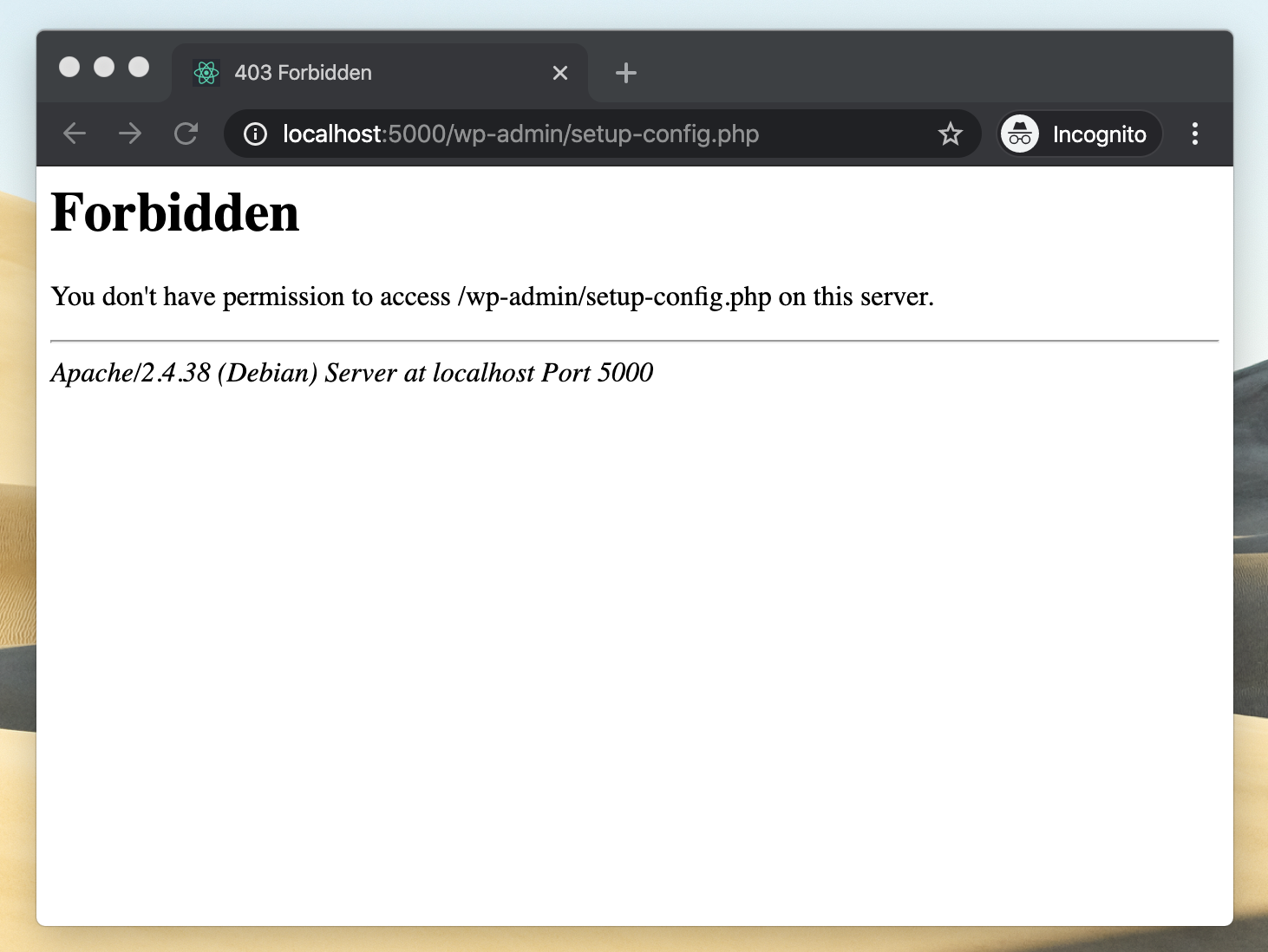
Initial results were a bit wanting.
This screenshot of an error might not look like much but there are a bunch of things that we might read out from this.
-
I had tried to navigate to
localhost:5000but was redirected to/wp-admin/setup-config.php. This suggests that the php code was able to start up. -
Furthermore, we see that
setup-config.phpwas attempted which suggests that the server did not find the database service, and then decided to try and setup a new database instead. Reasons for this happening could be some wrong connection configuration, that the server process isn’t able to access the database process or possibly a wrong version of the database.
But why were we getting access forbidden for the setup page? I rummaged a bit more in the codebase and found an .htaccess file within the wp-admin/ sub-folder. .htaccess files are used to configure the Apache web server, and this concrete file was setup to not allow access from anything except but a few ip-addresses. Since, I was just trying to make this code run locally there was no need for this security so I deleted that file and revisited localhost:5000.
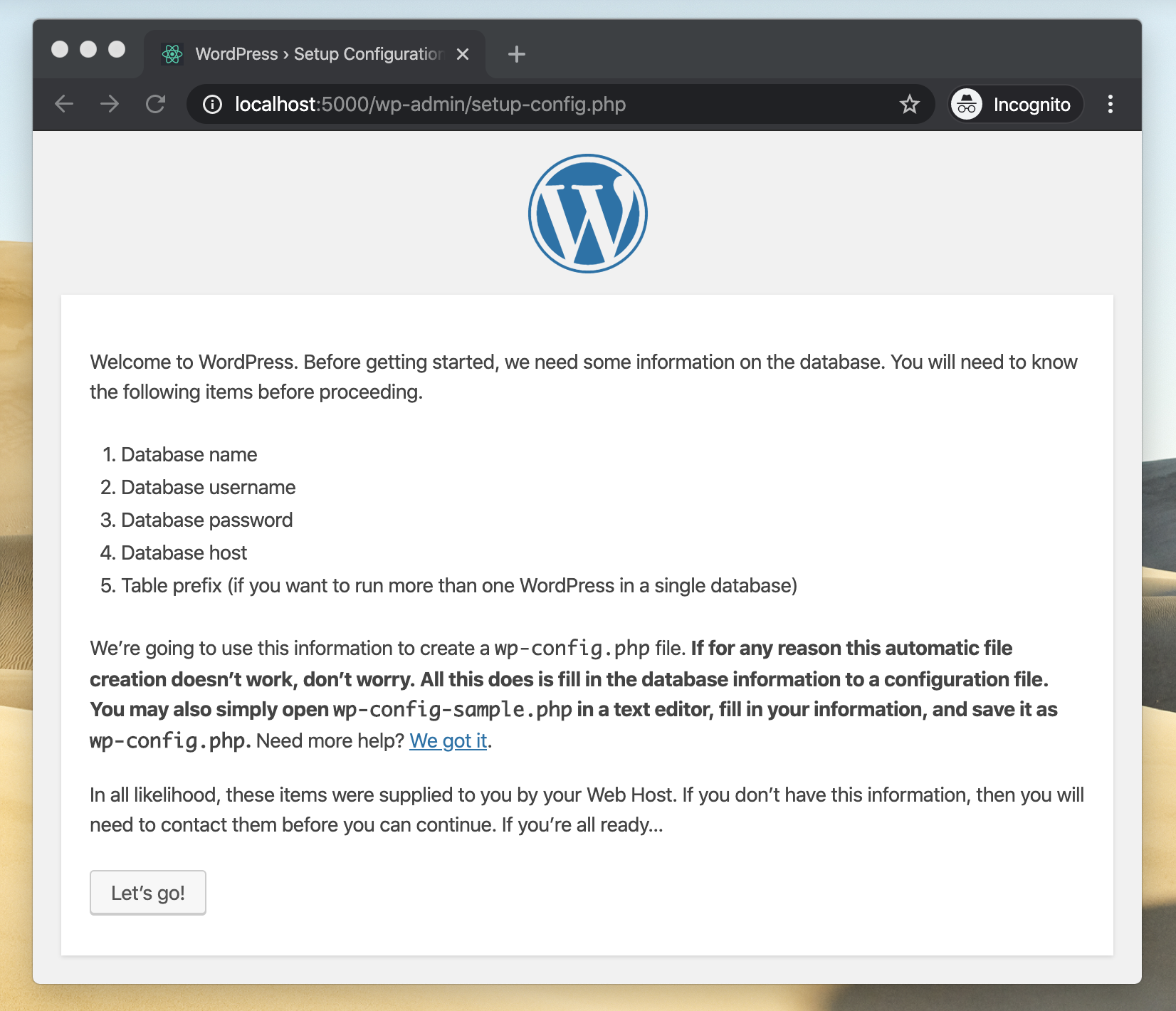
We’ve never been closer than this.
With the .htaccess file deleted we now got to see the actual setup screen. But why was WP trying to setup a new database? I suspected that either the data was not being loaded properly into the database, or that the web server was not able to connect to it.
I poked around some more.
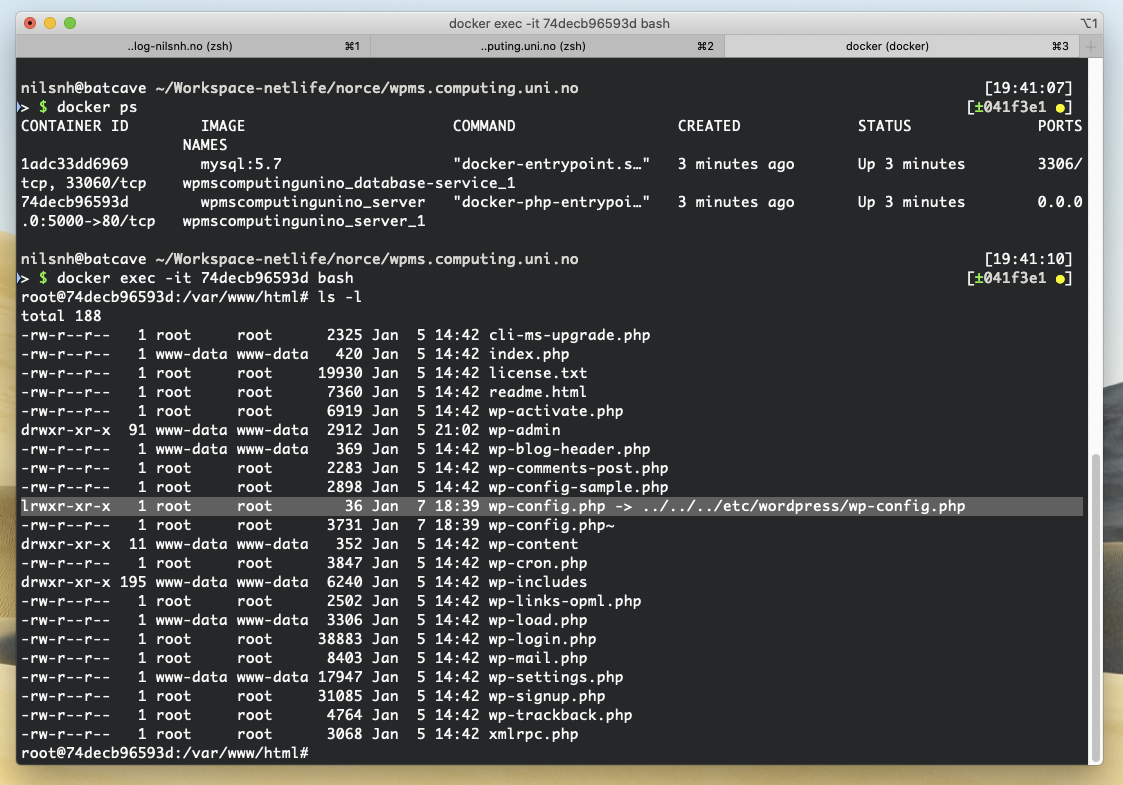
Now look at that highlighted line with the arrow.
I called docker ps to list out the running server environment. And then I used docker exec to spawn a terminal prompt inside the Docker container. This is a super useful move if you need to poke around inside a container for debugging purposes.
What I discovered was that the configuration file wp-config.php was expressed as a symbolic link (kind of like a shortcut) to a config file located elsewhere. It looked like I had the configuration file when I was rummaging through the WP files on my laptop, but when I mounted the WP files into the docker-compose setup I forgot to add an adjacent folder that contained the actual wp-config.php file.
I deleted the symbolic link and added the missing wp-config.php file.
Let’s see where that takes us.
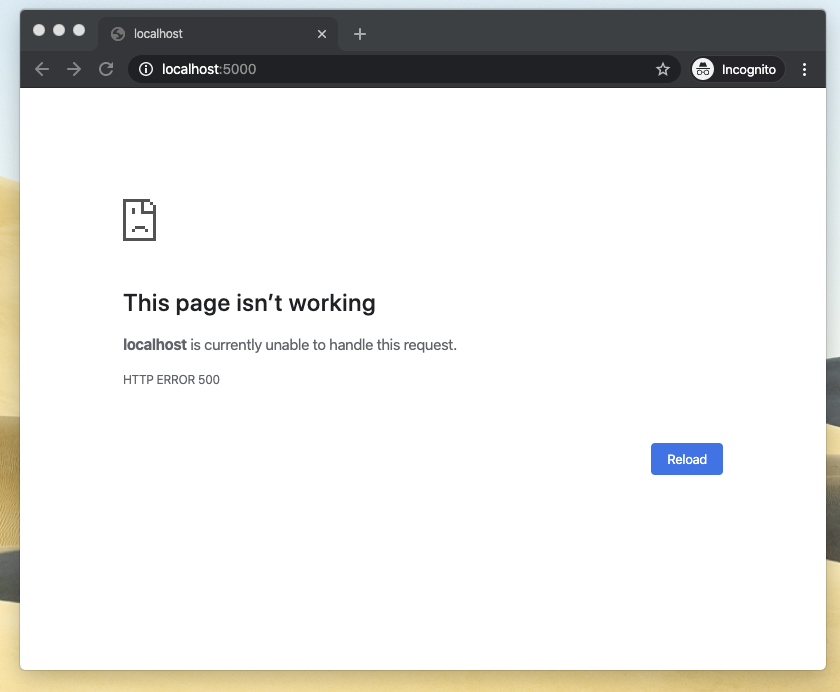
Hmm. Nothing.
So! The browser was now showing http status code 500 which means that there’s was some error on the web server. But what was the error. When I was editing the wp-config.php file I noticed that there were some settings for enabling errors in the browser so I went and activated all debug settings.
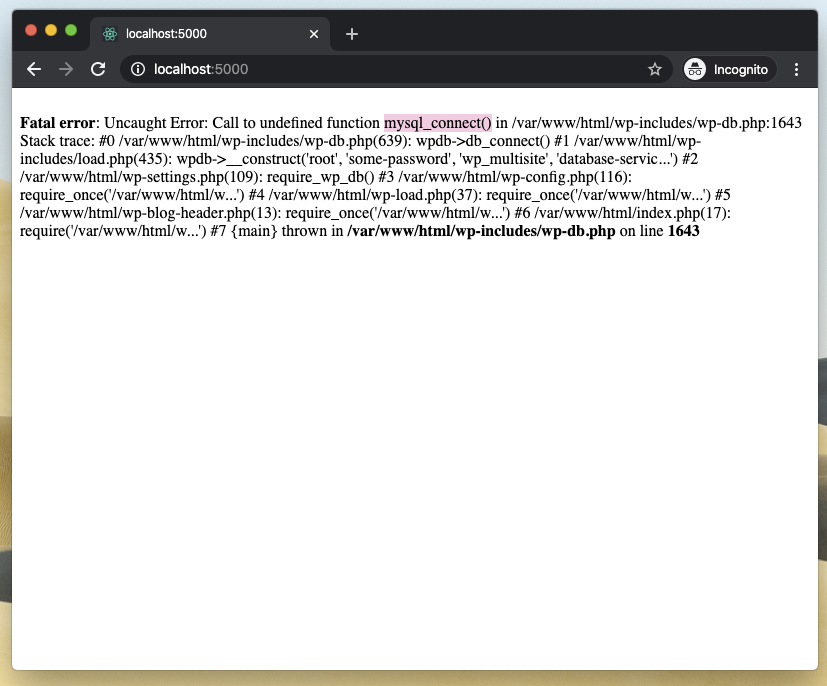
Now we’re getting somewhere.
The browser was now showing a stack trace error. Upon closer inspection it looked like PHP was trying to call mysql_connect() and failing. I looked the function up in the PHP documentation and learned that it was removed in the PHP version on my web server.
Luckily, Docker makes it real easy to switch an image for an older one. I dug in the PHP image archive and thankfully found an image with PHP 5.x version. So, I tweaked the Dockerfile until I had this result:
# Use ancient PHP image
FROM php:5.5.19-apache
# Activate .htaccess module(s) that WordPress needs.
RUN a2enmod rewrite
# Add php configuration to activate extra logging.
COPY ./000-default.conf /etc/apache2/sites-available
# Enable ancient PHP extension for mysql functionality
RUN docker-php-ext-install mysql
I restarted the web server setup and tried to access the web page once more.
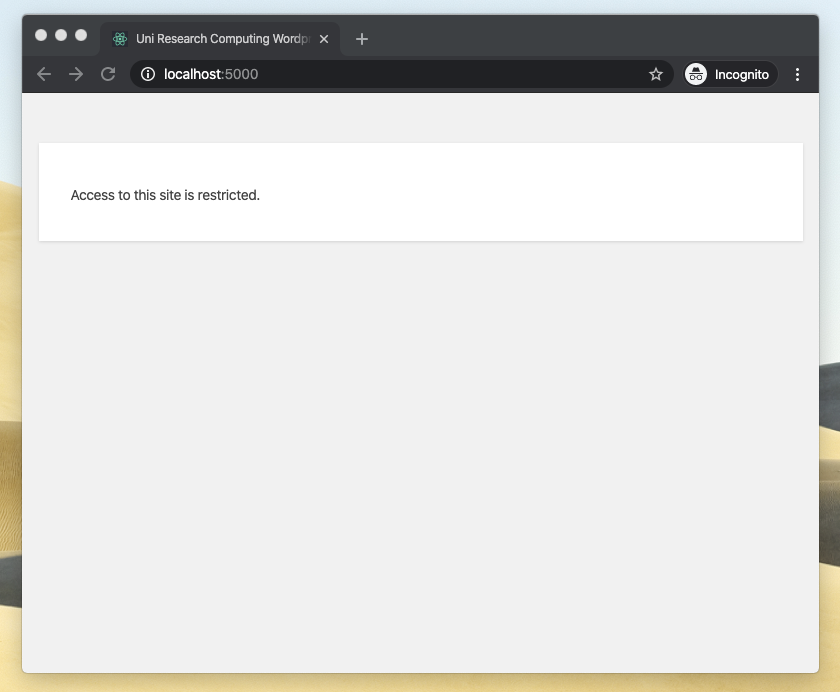
Success! (Actually).
My browser was finally showing the same frontpage as the live site.
I then tried to login.
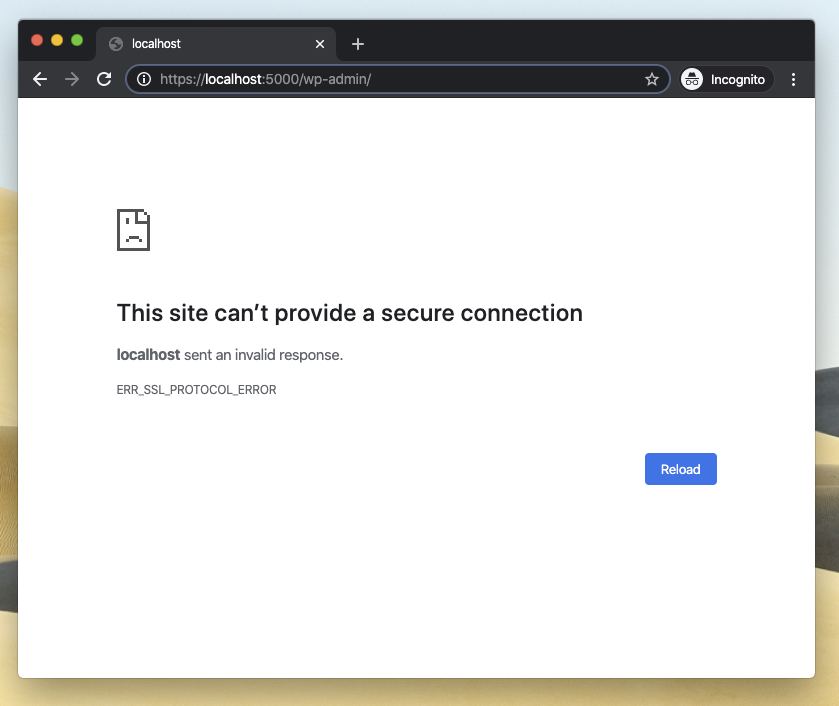
Alright, hmm. Some SSL error.
When I tried to access the wp-admin/ login page I got yet another error. WP was automatically trying to redirect to https meaning an encrypted SSL connection. It makes a lot of sense that WP enforces this, but right now I just wanted to access the site locally on my machine so this precaution was in my way.
I dove into the WP codebase once more in search of a fitting lever or knob. From the wp-config.php I saw that it included a wp-settings.php file, and inside it I did a search for the word “SSL” and found a function call named wp_ssl_constants();. I looked it up on the web and found that it did indeed control whether or not to enforce https for the admin pages. Yay! I then set FORCE_SSL_ADMIN to false.

Yes! But what was the password?
This was still in the middle of Christmas, and it dawned on me that I actually didn’t have the admin password. I had the WP files and a database copy, but it only contained encrypted passwords so there was no use looking inside the database for the password. Hmm.
Once more into search mode! I searched online and found that there’s a number of ways of how to reset a WP password. So, I went and used this one. I was surprised by how easy it was to give myself admin access.
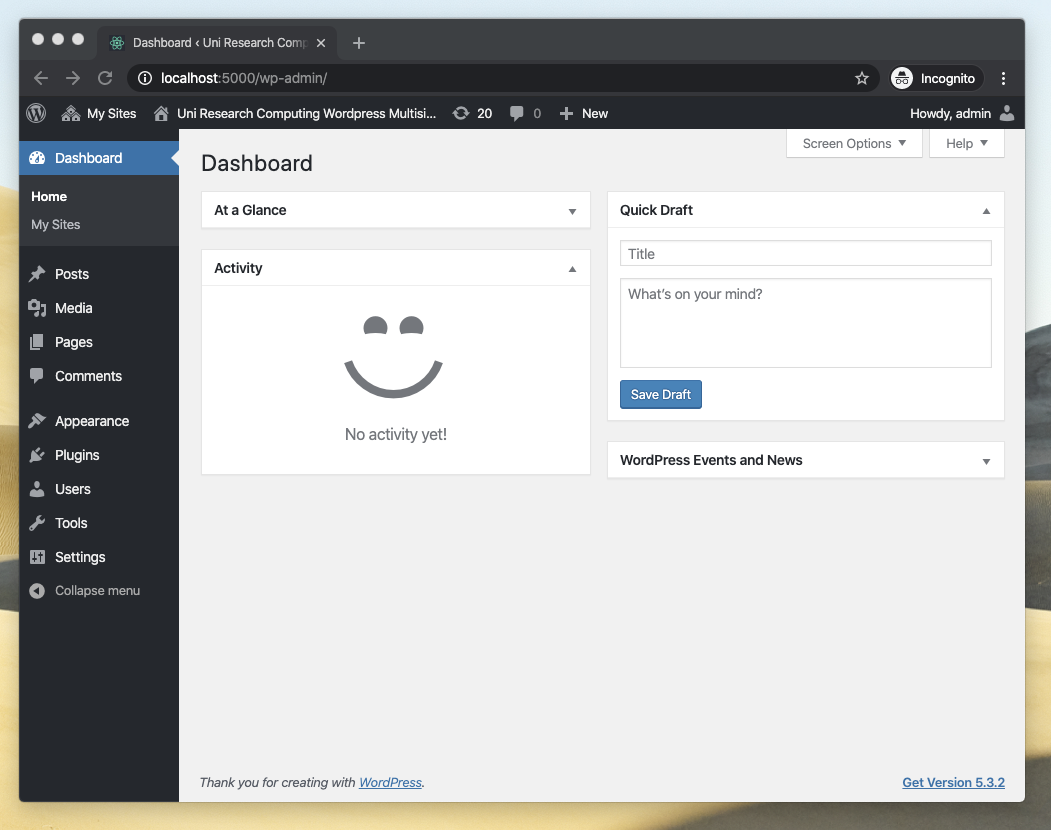
Finally! Inside.
Once inside I could make a number of changes to tailor all the sub-sites in the WP multi-site installation.
Changes included:
-
Deactivate any security plugins to avoid
wgetcrawling errors. -
One of the sites had several pages with letters such as ‘æøå’ in the url, I updated those urls so they no longer contained non-ascii characters.
-
Finally, I changed the empty Frontpage to be a a link list of all the pages that I wanted to archive. I could now point the
wgetcrawler at the frontpage and it would visit the sub-sites it needed to archive.
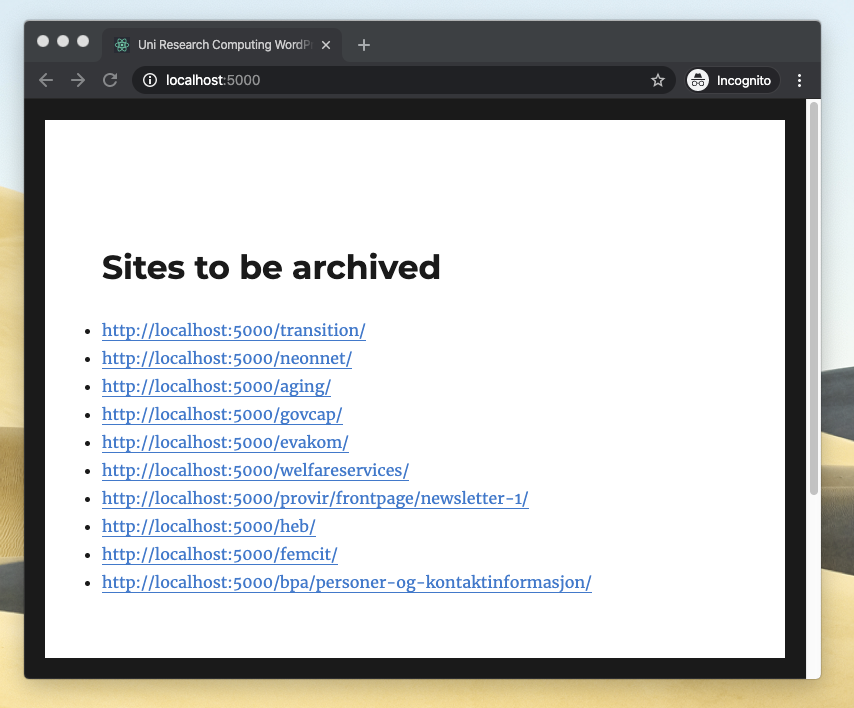
With the link list in place I could let wget get to work.
A moment to kick back with some coffee.

Since I was hosting the site and crawling it on the same machine I was able to get a decent throughput. Normally when web crawling you would add a small wait time between each web request to avoid getting ip-blocked by the target web server.
After running the crawler I spun up a local web server to look at the static files and initial results looked good when I clicked around.
Nevertheless, I wasn’t surprised to find some remaining link bugs but when I compared the failing links against the live site I discovered that they actually redirected back to the site I was archiving.
In other words I had links like this:
- sub.differentsite.no/site1/article
- wpms.example.org/site1/article
On the live site the link number one would eventually resolve to link number two which was the site I was archiving. But wget was only configured to archive localhost:5000, everything else looked like external domains to it and was skipped. To fix this I could’ve added the other domain to the crawling setup, but I landed on running a search-and-replace (regexp surgery) on the database so that these link redirects would point to the wpms.example.org domain directly.
I crawled, tested and crawled a bit more before uploading the final archive. Adding to that I also archived and documented this Docker setup, because who knows, we might need to re-crawl this WP site if some new issues crop up.
This ended up being a challenging assignment with all sorts of twists and turns. Beyond completing the task itself I was especially happy about doing it without any overtime (no need for heroics).
The work was done, I remember finishing it up a Friday afternoon in Christmas time. A plain workday was over. Four o’clock was fast approaching. I arose from the living room chair, and with my mug in hand I followed the house cat into the kitchen for some more coffee.