Case study: Archiving web sites with wget and puppeteer
 Nils Norman Haukås
Nils Norman HaukåsOne does not simply archive web sites in 2019. Join me for an adventure in web site crawling.
At Netlife I helped build norceresearch.no for NORCE, which is a research institution formed by joining several well established research institutions. And while building their new site it became clear that there was a need to also archive the web sites that would be replaced by the new research institution.
The web sites to be archived were cmr.no, teknova.no, norut.no, agderforskning.no, uni.no, iris.no, prototech.no and polytech.no. Some sites were soon to be phased out, while others were archived just in case. These sites were built and hosted by various firms including NORCE itself.
My approach had two parts. One, I would get in touch with the various web site administrators and request a copy of the codebase and the database. Two, I would apply the Swiss army knife that is wget for creating static exports of the sites. wget is a command line tool initially released in January 1996. It’s feature-rich, mature and a real workhorse.
I got to work by sending a flurry of e-mails, before getting to work by archiving iris.no with wget. And as luck (or bad luck) would have it it turned out to be no easy feat.
#!/usr/bin/env bash
DOMAIN=$1
START_URL=$2
wget \
--mirror \
--page-requisites \
--html-extension \
--convert-links \
--domains $DOMAIN \
--rejected-log=$DOMAIN-rejected.log \
--directory-prefix=site-$DOMAIN \
$START_URL
See command line flags explanation (thanks Explainshell!).
I prepared this command as a script I could re-run for the various sites. And then I called it with ./wget.sh iris.no www.iris.no and excitedly awaited its result.
The script saved its output to a site-iris.no folder and I fired up a local web server in the folder with:
(cd site-blog-iris.no && python2 -m SimpleHTTPServer 9090).
Sidenote: Calling a command with parenthesises lets you run a command inside a directory without switching to it. Super useful if you’re dealing with a command that requires you to be in the target folder.
I navigated to the local web server to check out the archived site.
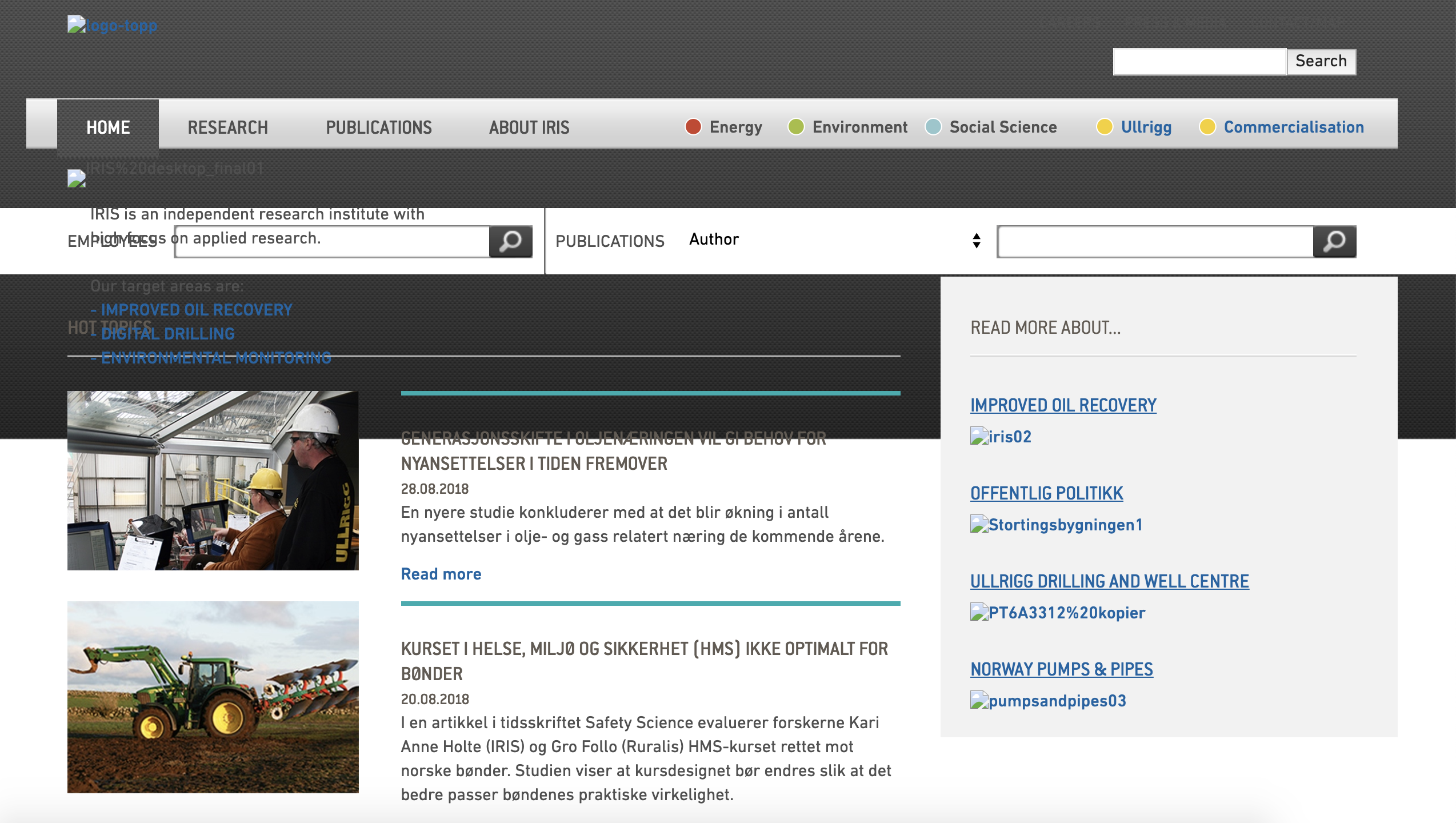
“Houston, this is going to take a little more work.”
Now, isn’t this a slice of real developer life?
My mind raced as I was sitting at my desk, sipping coffee and considering this screenshot. wget doesn’t process javascript, and this site apparently needs it to lazy load its images.
I considered my alternatives and I suspected that Puppeteer could be a worthwhile tool to check out. It’s essentially a project for remote controlling the Chromium browser. After some more searching I found that someone already had tried to create a web scraper with puppeteer called website-scraper-puppeteer. On further inspection I learned that it was a plugin to another project called website-scraper which seemed actively maintained and well tested.
Using the website-scraper package I built a proof of concept for downloading just the iris.no frontpage, if I could successfully deal with the lazy loading images on the frontpage the fix should work for the rest of the site. After some tinkering I got my code to successfully download the frontpage with images included. Yay!
I then cautiously flipped the recursive switch to get my code to start crawling iris.no by jumping from link to link. I let the program run for a bit, but it was somehow not making progress. Or maybe it was just not reporting very well what it was doing or struggling with. After some hours I force-quit the program and checked out whatever it had archived. And it didn’t look promising, it was as if it wasn’t able to store the web pages properly.
At this point I had on one hand this mature wget command line utility with all sorts of good functionality for archiving web sites just lacking javascript support. And on the other side I had this website-scraper package where I was able to tackle javascript pages, but I wasn’t sure if it was able to properly crawl sites. Besides these two approaches I could as a last resort try and write my own custom crawler but that would surely blow the constrained project budget.
When in doubt, ask for help #
When you’re stuck on a problem it helps to bounce ideas with colleagues. So, I started a chat thread and asked my colleagues to chime in. I explained everything I’d tried and they suggested I’d have a look at phantom.js, jsdom or a python package called Beautiful Soup.
I read their advice and I typed out my thoughts in chat on whether or not I could put a proxy between wget and the web site it was trying to archive. This proxy would briefly browse the web site using Puppeteer letting javascript do its thing and lazy load images. After rendering the page the proxy could then hand the web page content back to wget which would not need to know anything about javascript because the proxy handled it.
To see if I could create a proof of concept I wrote a small web-server in Node.js. And to get wget to hit the proxy server instead of the actual website I updated my laptop’s hosts file.
By editing the hosts file you can do things like making web requests to twitter.com go to any random ip address instead, for instance 127.0.0.1 (your laptop’s home address). It’s useful for testing and for making it a little harder to reach addictive web sites (like Twitter or the like).
I soon saw that adding domains to the hosts file wasn’t a scaleable approach. Ideally, I needed to make wget always use the proxy but using the hosts file I now realised that I would have to enumerate all the domains and sub-domains wget could encounter while traversing iris.no’s links. Thankfully, after poring over wget’s extensive documentation I saw that it had a proxy feature (off course it has, silly me, wget has everything).
Excitedly I built a proof of concept around wget + proxy and it worked!
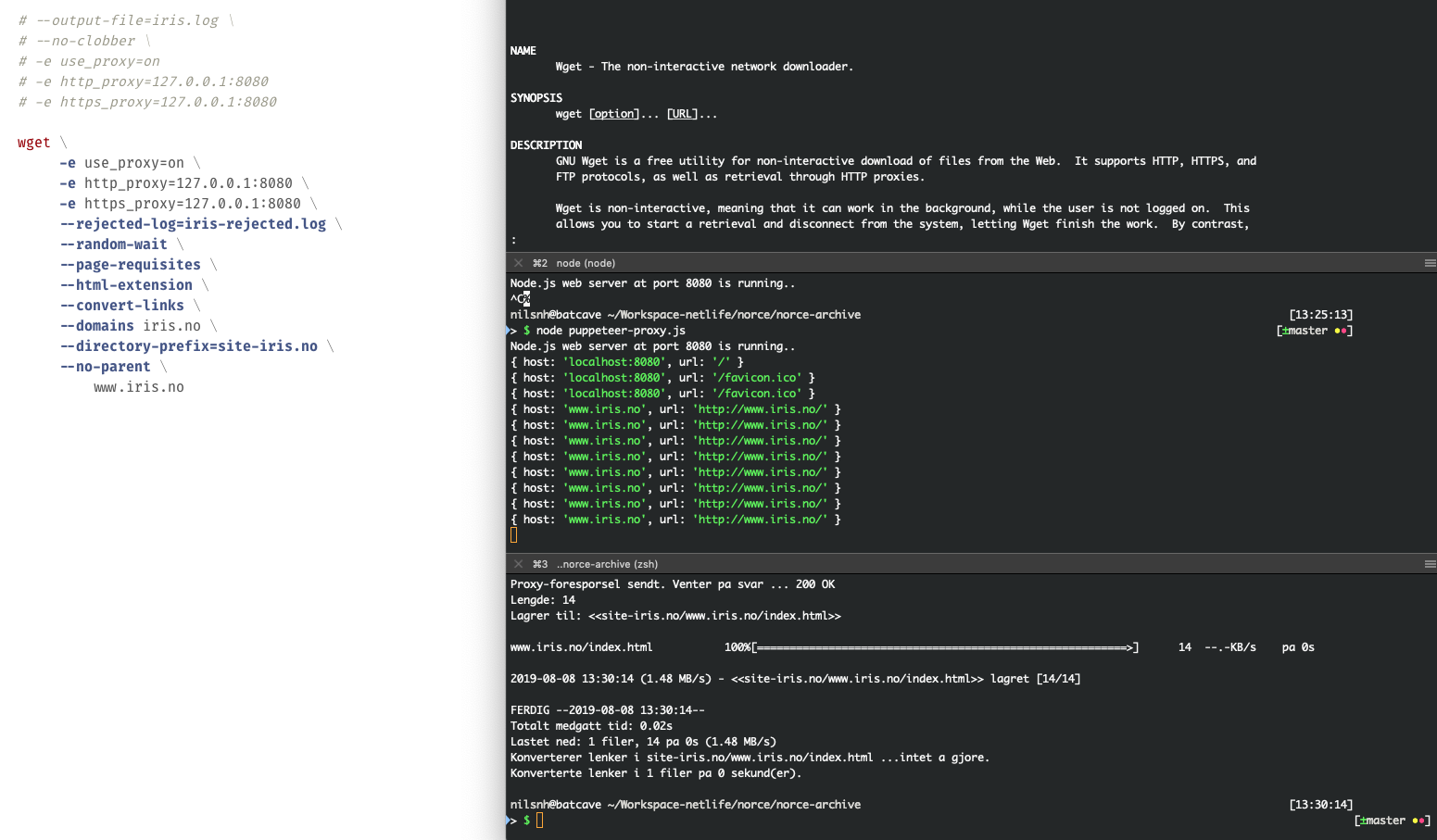
To the left there’s the wget script with proxy flags activated. To the right there’s three terminal tabs containing wget documentation, the running proxy and finally the results of running the script. So then this proof of concept was proven.
I then built a simple proxy server in Node.js and named it puppeteer-proxy.js, here’s the code for it. I’ve added comments for clarity.
const http = require("http");
const puppeteer = require("puppeteer");
const fetch = require("node-fetch");
let browser;
const server = http.createServer(async (req, res) => {
// We look at the proxy request and figure out the url
// the client (wget) wants to fetch.
const { url = "/" } = req;
try {
// Make a network request, and figure out
// what lies beyond the url. It could be a web page,
// an image, a video or something else.
const fetchResult = await fetch(url);
const headers = fetchResult.headers.raw();
console.log("Processing", { url });
console.log({ headers });
const { "content-type": contentType = [] } = headers;
res.writeHead(fetchResult.status, {
["content-type"]: contentType
});
if (contentType[0] === "text/html") {
// If the content is a web page we fire up puppeteer
// to help us lazy load all images. See parseWithPuppeteer
// function.
const text = await fetchResult.text();
const modifiedText = await parseWithPuppeteer({ text });
res.write(modifiedText);
res.end();
} else {
// For everything else we just send the fetched contents
// back to wget.
fetchResult.body.pipe(res);
}
} catch (err) {
// If something goes wrong we need to respond with proper
// status code so that wget can move on instead of waiting
// endlessly for a response.
console.log("Failed to parse url", { url, err });
res.status = 500;
res.end();
}
});
const parseWithPuppeteer = async ({ text }) => {
const page = await browser.newPage();
await page.setViewport({
width: 2560,
height: 10000
});
// Take the html text and insert it into the browser,
// this will run its javascript and load any resources.
// We tell puppeteer to wait until the network is idle.
await page.setContent(text, {
waitUntil: "networkidle0"
});
// Finally! This is the meat and potatoes where our
// proxy can have puppeteer make sweeping changes to the
// html. This code is tailored to the lazy loading functionality
// found on the iris.no web site.
await page.evaluate(() => {
// Manually lazy load all images on the page by rewriting
// the html so that invisible references to images becomes
// visible to the browser and thus downloadable.
document.querySelectorAll("[data-src]").forEach(el => {
el.setAttribute("src", el.getAttribute("data-src"));
el.removeAttribute("data-src");
});
// Remove .lazyload classes to prevent the page's javascript
// from trying to lazy load these images when we view the
// archived web site in the future.
document.querySelectorAll(".lazyload").forEach(el => {
el.classList.remove("lazyload", "lazyfade");
});
// Scroll to the bottom of the page to trigger lazy loading
// just in case if there was something we missed out on.
window.scrollTo(0, document.body.scrollHeight);
});
// Wait a bit to give the site a chance to load any images,
// before pulling the changed html out of the browser and
// passing it on.
await page.waitFor(100);
const content = await page.content();
await page.close();
return content;
};
// The initialisation code that opens a hidden browser ready
// to parse html and starts the web server.
(async () => {
browser = await puppeteer.launch({ headless: true });
const port = 8080;
server.listen(port);
console.log(`Node.js web server at port ${port} is running..`);
})();
// Ensure that we close the hidden browser when the process exits.
process.on("SIGINT", () => {
browser.close();
});
I finally had a good setup for handling the lazy loaded images found on iris.no. I fired up wget and let it crawl iris.no. While it was running I went and started crawling jobs for all the other sites.
The top, leftmost window contains logging output from proxy. The rest of the top row and second row is occupied by six wget processes busy crawling sites. The left window in the third row runs a local copy of norceresearch.no and finally there's an unused command line prompt.

After resolving the challenges with iris.no I was pleased to learn wget had no problems downloading these sites:
- cmr.no
- teknova.no
- agderforskning.no
- prototech.no
- polytech.no
However, wget ran into trouble while archiving norut.no and uni.no. wget was simply not able to completely traverse the sites. It was hard to gauge their progress so I tried letting the jobs run overnight but when I checked on the scripts the next day they were still running.
When I looked into the archiving logs for norut.no I saw that it was spending a lot of time visiting urls with the word “filter” in them. It turned out that the search had various ways to filter the search content, and these filters were expressed as links that wget would follow. This led to an exponential tree of possible routes that wget could take as it would try to click the various filter links in all sorts of combinations and then follow each and every page in the search result.
Ideally, wget should just see norut.no’s search page without any filter links because then it would just page through all the search results only once. This was a perfect use case for the proxy but my simple proxy implementation turned out to have issues with https. While I was able to proxy iris.no on an http connection, norut.no enforced https (which modern sites should do). My wget script would simply error in weird ways when trying to reach norut.no and it took a little while to narrow the problem down to stemming from https.
Https is a means to establish secure communication online. When you log into your bank’s website https protects you from eaves dropping or man-in-the-middle (MiTM) attacks. So, the errors thrown was just wget protecting me against possible attacks (even though it was my proxy standing in the middle).
My naive proxy had quickly got me to a place where I could download iris.no, but for the remaining sites it looked like I needed more mature proxy software. I looked around and found anyproxy.io which seemed nicely extensible using a rule system.
Moreover, it had proper support for proxying https traffic. That’s a key benefit of working with mature software, they’ve already run into and figured edge cases you did not even consider.
I wrote rule sets for each site, and I’ll share one of them. Please have a read and I’ll see you below the code.
const puppeteer = require('puppeteer')
// Spin up a browser in the background
let browser
const setupBrowser = async () => {
puppeteer
.launch({ headless: true, ignoreHTTPSErrors: true })
.then(builtBrowser => {
browser = builtBrowser
browser.on('disconnected', setupBrowser)
})
}
setupBrowser()
process.on('SIGINT', () => {
browser.close()
})
// Build an Anyproxy module following its specification.
module.exports = {
// introduction
summary: 'Puppeteer rules for anyproxy',
// intercept before making send request to target server
*beforeSendRequest(requestDetail) {
const {
url,
requestOptions: { path, hostname },
protocol,
} = requestDetail
// If the url contains an at-symbol we 404 it. This
// avoids confusing wget. When crawling I encountered
// email urls that returned the uni.no site leading wget
// to start traversing the site from there as if the
// email was a new domain. This had to be mitigated.
if (new RegExp(`/https?:\/\/.*@${hostname}`).test(url)) {
return {
response: {
statusCode: 404,
header: { 'content-type': 'text/html' },
body: '',
},
}
}
// Avoid errors from the faulty certificate on cms.uni.no. I
// first restricted the crawling to uni.no, but then discovered that
// the whole site was available on cms.uni.no. And I would much rather
// restrict the crawling to the cms. subdomain to increase chances of it
// completing. This wasn't straightforward since the https certificate
// was only setup for uni.no. So, any https requests to cms.uni.no would
// throw a certificate error. This was finally fixed by pre-modifying
// any https requests to http.
if (hostname === 'cms.uni.no' && protocol === 'https') {
return { protocol: 'http' }
}
return null
},
// deal response before send to client
*beforeSendResponse(requestDetail, responseDetail) {
const { url } = requestDetail
const { 'Content-Type': contentType = '' } = responseDetail.response.header
if (contentType.split(';')[0] === 'text/html') {
const html = responseDetail.response.body.toString('utf8')
return browser
.newPage()
.then(async page => {
await page.setViewport({
width: 2560,
height: 10000,
})
await page.setContent(html)
await page.evaluate(() => {
// Remove list of year filters on uni.no. No need
// to have wget following various filters because the
// default is to display all the content we wish to archive.
document.querySelectorAll('.widget.years').forEach(widget => {
Array.from(widget.getElementsByTagName('ul')).forEach(ul => {
Array.from(ul.children).forEach(li => {
if (li.textContent.indexOf('Alle år') !== -1) {
// do nothing
} else if (li.textContent.indexOf('All years') !== -1) {
// do nothing
} else {
li.remove()
}
})
})
})
window.scrollTo(0, document.body.scrollHeight)
})
const newResponse = responseDetail.response
newResponse.body = await page.content()
await page.close()
return {
response: newResponse,
}
})
.catch(err => {
console.log('Failed to render url', url, err)
})
}
return null
},
// if deal https request
// *beforeDealHttpsRequest(requestDetail) {
// /* ... */
// },
// error happened when dealing requests
*onError(requestDetail, error) {
/* ... */
},
// error happened when connect to https server
*onConnectError(requestDetail, error) {
/* ... */
},
}
After nailing these rules sets there was but one challenge left. Uni.no had some very interlinked content that still sent the wget crawler around in an infinite loop. I ended up solving it with this custom shell script.
#!/usr/bin/env bash
# Departments was tricky to archive because they had a lot of cross-links.
# I solved that by restricting what areas it was allowed to jump to.
DOMAIN=cms.uni.no
PROXY_PORT=9001
wget \
--recursive \
--level=inf \
--timestamping \
--page-requisites \
--html-extension \
--convert-links \
--no-check-certificate \
--include /nb/avdelinger,/nb/news,/nb/uni-cipr,(... several more urls ...) \
-e use_proxy=on \
-e http_proxy=http://127.0.0.1:$PROXY_PORT \
-e https_proxy=http://127.0.0.1:$PROXY_PORT \
--domains $DOMAIN \
--rejected-log=$DOMAIN-rejected.log \
--directory-prefix=site-$DOMAIN \
http://cms.uni.no/nb/avdelinger/
And so this archiving journey came to an end. And on project budget even.
I learnt a lot about web site particularities, about proxies in general and how wget truly is a Swiss army knife. I hope this writeup will help anyone undertaking similar web archiving projects.
Big thanks to the project maintainers behind all the tools I ended up using.
Thanks for the read!